Overview
The Object Detection module represent the challenge of identify and locate objects in the environment. This module is used in computer vision and image processing to detect objects in an image or video sequence. The goal is to identify the object and its location within the image or video frame. The module uses various techniques such as feature extraction, object recognition, and machine learning algorithms to achieve this task.
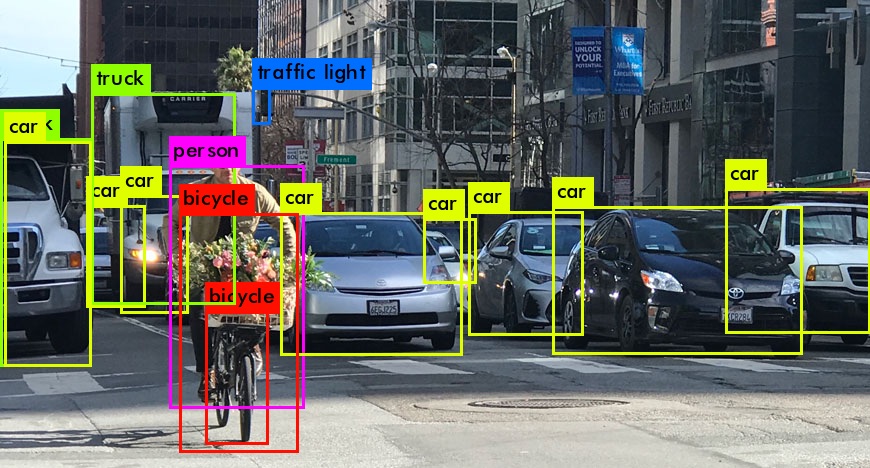
Challenges and Tasks
The Object Detection module is focused on produce a highly accurate while fast object detection system. The first approach for this in the first year of participation, was to use a pre-trained model based on the Object Detection API from Tensorflow. This model was trained with the COCO dataset, which contains at most 4 different classes of objects. The process was to generate the dataset from a manually labeled dataset of images, and train the model with it.

This approach had several problems listed below:
- The model was not accurate enough to be very confident in the detections.
- The model was not fast enough to be used in real time.
- The classes of objects where limited and if we wanted to add more classes, we had to use a different model.
- The labeling process was very time consuming and tedious.
To solve this problems, we decided to use a different approach. We decided to make two big improvements to the system. The first one was to automate the dataset generation process, making it faster and easier to generate and improving the dataset quality. The second one was to experiment with different pre-trained models and different Object Detection Algorithms. With the use of different models and algorithms, we conclude that the Yolov5 model outperformed the other models in terms of accuracy and speed.
- Dataset Generation
- Customly Trained Object Detection Models